I spent the last week building our company’s AI chat assistant. It started innocently: I would handle the UI and the front end, and the rest would come later, from someone else. Then the project spiraled, in the good way. By the end of the week I had implemented the entire stack: the chat drawer, the API routes, the planner, the conversation store, the eval harness, and the LLM judge that grades the answers against written floors.
That was unexpected, and more exciting than I’d like to admit.
The stack
Sparky is the in-dashboard assistant for our enterprise energy platform. Operators ask it things like “which buildings have open alarms?” and it answers from live portfolio data, scoped to what that operator is allowed to see.
Only two pieces are genuinely new: a turn store and an eval harness. Everything else is infrastructure the dashboard already trusts. Here is what each layer is and why I reached for it.
Sparky lives inside the existing dashboard instead of as a separate app, so it inherits the same login and permissions automatically, and there's nothing new to deploy.
Handles the back-and-forth with the model and streams each reply into the drawer as it's written, so I didn't have to build that plumbing by hand.
One doorway to every AI provider. Which model answers and which one grades are just settings, so I can swap either without changing code.
Each incoming request is checked against a strict shape before anything runs, so bad input is caught at the door and comes back as a clean, predictable error.
Stores the conversations, feedback, and usage limits in production. On my laptop the same setup runs entirely in memory, so there's no database to install just to develop.
The test suite and the eval gate run automatically on every change, and block anything that would break Sparky from shipping.
System design
Here is how a single answer works, from the moment someone asks.
Both ask Claude Sonnet 4.6 through the Gateway
Most of that path is ordinary plumbing. A few steps carry a decision worth explaining.
The rate limit fails open. Each person gets a cap on how many questions they can ask in a short window. If the thing that tracks that cap is ever down, the question still goes through. That sounds backward until you ask what the cap is for: it limits cost, not access. A safeguard against overspending shouldn’t be able to take the whole assistant offline.
A conversation belongs to one person. The first message claims the conversation for whoever sent it; every later message checks that the same person still owns it and refuses if not. So nobody can pick up someone else’s thread, and it’s settled on the very first turn.
Sorting the question is a quick pattern match, not an AI call. Before any model is involved, the question is sorted into a kind: a how-to about the product, or a question about live building data. The clever part is catching follow-ups. “Why do they have alerts?” names nothing on its own, but if a vague “they” or “those” shows up soon after a data answer, Sparky treats it as a follow-up about that same data instead of starting over. That one rule killed a whole class of confused replies.
The model proposes, the code decides. For a data question, a model gets the question, the recent conversation, the tools it’s allowed to call, and, most importantly, the exact list of which buildings and sites this person is allowed to see. It comes back with a plan: which tools to run, a clarifying question, or a refusal. Before anything runs, the code re-checks that plan against the person’s permissions. The model suggests; it never grants access.
Working out which buildings a question is about follows a simple order: a name in the question wins, words like “we” or “overall” mean the whole portfolio, and otherwise it falls back to the page you’re already on. That last rule came from watching real questions: someone who just opened a site’s page and asks “how’s it doing?” means that site, not everything.
Actions are refused with a place to go. Sparky can read, not change. Ask it to “acknowledge that alarm” and it declines, but points you to the page where you can actually do it. A refusal that hands you the next step reads as helpful; a flat no reads as broken.
That last step, saving the turn, is where memory used to quietly break. The first version kept two separate lists, one for bookkeeping and one for the messages, and trusted them to stay in sync. They didn’t. And both lived only in the server’s memory, so every redeploy wiped every conversation. Sparky lost its memory on a schedule and nobody noticed, because nothing ever errored.
Now each exchange is saved as a single record:
type SparkyTurnRecord = {
threadId: string;
turnId: string;
query: string; // what the user asked
capability: Capability; // which path answered it
answerSummary?: string; // what Sparky actually said
scopeLabel?: string; // what it was looking at
currentRoute?: string; // where the user was standing
locale?: string;
userScopes?: string[]; // permissions at answer time
modelId?: string; // which model answered
createdAt: string;
};It keeps what Sparky actually said in plain words (“Stockholm Campus has three open alarms”), so a follow-up like “why?” has a real sentence to point back at instead of a category label. The rest of the fields, who asked, what they could see, which model answered, never go into an answer; they exist so a turn can be replayed exactly, which is what makes the feedback loop possible.
Evals: two layers, and a blind judge
Before any change ships, a fixed set of saved answers is graded, in two layers. The order matters: the cheap, strict checks run first, and the slower judgment only runs if those pass.
Layer one is a checklist a machine can run. Sixty saved examples go through a set of plain pass-or-fail checks. Is the answer the right shape, in the right language? Does it include the facts it should and leave out the words it shouldn’t? Does any internal jargon (“scope”, “rows”) leak into what the user sees? If it’s a refusal, does it actually refuse, without pretending the action got done? All sixty have to pass. If even one fails the run is over, because there’s no point paying a model to judge an answer that’s already broken.
Layer two is a second AI that grades the answer without ever seeing the right one.
judge.invoke({
frame: { query, capability, currentRoute, priorTurns },
requiredFacts: [ …per-fixture checklist… ],
voiceGuideExcerpt: "…",
goldenAnswer: "the expected answer text…"
})An earlier version handed the judge the whole example, model answer included. The scores looked great and meant nothing: a judge holding the answer key is really just checking whether two strings match. Now it sees only the conversation, the data the tools returned, a checklist of facts the answer must contain, and a short style guide. Never the answer itself.
It grades five things, like relevance and directness, against written definitions: for relevance, a 1 means it answered a different question, a 3 means on topic but vague, a 5 means direct and complete. The grading form is ordered on purpose, too. The judge has to settle each required fact first (supported, contradicted, or missing) and explain itself before it can write a single number, the same conclusions-before-scores discipline I’d ask of a human reviewer.
Three more habits keep the grading honest:
- Same answer, same score. Randomness is turned off, so repeated runs measure the judge’s consistency, not luck.
- Middle of three. Small sets are graded three times and the middle score kept; if the three disagree by more than a point, the case is flagged for review instead of being quietly averaged.
- No family loyalty. The grader is from a different company than the writer: OpenAI’s GPT-5 grades Claude’s answers. If it is ever misconfigured into a model grading itself, the scorecard says so out loud.
One bad answer fails everything. Averages hide problems: one terrible answer disappears among fifty-nine good ones, and the terrible one is what gets screenshotted. So the suite never passes on its average. A case passes only if every score clears the bar; an answer that claims something the evidence doesn’t back is capped low; and a single failing case fails the whole run. The average is still reported, but only to watch for drift. It decides nothing.
The judge is tested before it’s trusted. Before grading anything real, it grades four answers planted to fail: a wrong count, an invented building, one that ignores the previous question, one that’s pure jargon. If the judge lets any of them through, the entire run is thrown out. A judge you haven’t tried to fool is a judge you can’t trust.
The whole suite lives in one folder:
Evals: a continuous self-improvement process
Those two layers grade what exists today. The other half of the system is how the set of examples grows: every real complaint turns into a new test.
Under every answer sit thumbs up and down. A thumbs-down with a note does real work on its own: the exact moment is captured as a candidate test, carrying the details needed to replay it later (the language, what the person could see, which model answered) plus the last eight turns of the conversation. This is why each saved turn keeps fields it never uses to answer.
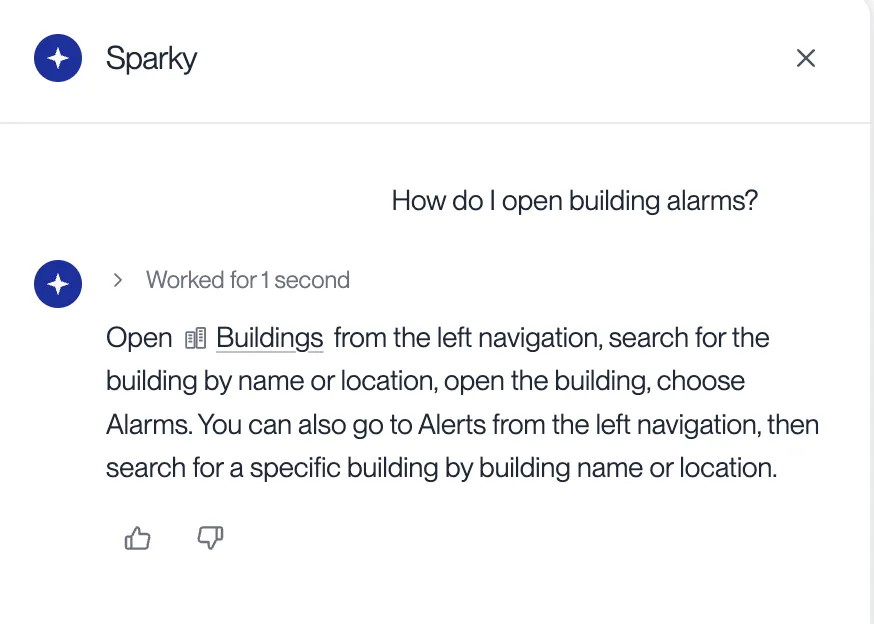
A nightly job gathers the new candidates for review. A reviewer reads each one, and when it’s a real miss, writes the answer Sparky should have given. That corrected answer becomes a regression test that every future change has to pass. The file starts empty and fills one complaint at a time. And if the person flips back to thumbs-up, the candidate quietly withdraws itself.
I should be clear about who that reviewer is: so far, it has been me, writing the corrections, not an independent human. The pipeline enforces an approved-reviewer list, but I am the one approved name on it. So these corrections are still my judgment, not verified truth, which is exactly the gap the scorecard owns up to below.
The feedback button is also not allowed to lie. If the note can’t be saved, the screen says so and lets you retry; it never shows a fake “Thanks!”. A feedback channel that swallows failures just trains people to stop reporting, which is the most expensive silence there is.
The latest judged run, unedited:
The average looks great, and the gate still says no. It’s right to. A couple of answers fall below the floor, and most of the answers it grades against are still Sparky’s own words, not anything a person has signed off as correct. That’s the whole reason it grades on floors instead of averages: one real problem is enough to fail the run. I’ll know it’s working the day this scorecard turns boring.
A short-lived Fable
The entire Sparky infrastructure took seven days to build, paired between Claude Opus 4.8 and Codex 5.5. Then a short-lived Fable 5 went over all of it with one instruction, be adversarial, and caught 63 findings across six work packages. The hardening pass worked through every one, each commit citing the finding it closed.
Sixty-three sounds like sixty-three separate mistakes. It mostly wasn’t. Almost all of them clustered in two places: memory and the evals. Sparky’s memory lived only in the server’s memory, so every restart wiped every conversation, and it barely recorded what it had said anyway, which together were behind a good third of the findings. And the evals graded Sparky against recordings of its own past answers, so they could only ever agree with it, which was behind most of the rest.
Both had clean fixes. Moving conversations into a real database closed the first. The blind judge closed the second, though it left a tail: until someone rewrites those recorded answers by hand, the scorecard keeps the gate shut, which is what it’s doing now.
The harness was the point
Today, Sparky handles two kinds of questions, the product guide and live building data, but nothing in the design is tied to either. The turn store doesn’t care what was asked, the planner doesn’t care what tools it runs, and the judge is blind to the domain, checking only that the facts hold up. That makes it easy for other teams at Thiink to pick up the same infrastructure when they’re ready.
I’ve also started exploring an on-premise build for our operator customers, whose data sometimes can’t leave their own walls when they onboard their buildings. Same architecture, running on their own hardware, with the answering model swapped from Claude in the cloud to a local Gemma served by Ollama. But that’s an article for another day.
Further reading
- Forge: When Product, Design, and Engineering Blur, the agent harness this was built with.
- From Insight to Implementation, the AI-native workflow behind the design phase.
Written by me via Wispr Flow. Reviewed and polished by Yuki (Claude Code).